

A powerful full-text search in PostgreSQL in less than 20 lines
Need a full-text search? PostgreSQL is good enough. Give it a try.


This blogpost will guide you to understand the fundamental pieces needed to implement a good enough full-text search using PostgreSQL.
Spoiler alert: for those curious people looking for a "okay, just show me a full-text search with ranking and fuzzy search in Postgres in less than 20 lines", so here you go:
SELECT
courses.id,
courses.title,
courses.description,
rank_title,
rank_description,
similarity
FROM
courses,
to_tsvector(courses.title || courses.description) document,
to_tsquery('sales') query,
NULLIF(ts_rank(to_tsvector(courses.title), query), 0) rank_title,
NULLIF(ts_rank(to_tsvector(courses.description), query), 0) rank_description,
SIMILARITY('sales', courses.title || courses.description) similarity
WHERE query @@ document OR similarity > 0
ORDER BY rank_title, rank_description, similarity DESC NULLS LAST
But if you need to understand what the heck is the above SQL statement doing, let me explain you a bit of context and FTS (Full-text search) fundamentals in PostgreSQL.
Context matters
A bunch of years ago I read this awesome blogpost called "Postgres full-text search is good enough". It's really worth reading, I could get many insights, since I was already using PostgreSQL as my standard database.
By the time, I was comfortable using ElasticSearch for text searching (and if we go even before that back to 2009, I have experience using Apache Lucene, from which ElasticSearch is based on).
However, managing ElasticSearch deployment is not easy. It requires a lot of patience and memory 🍪.
Then back to 2014 I wrote this article explaining the reasons why I decided to experiment on PG text search as well as showing a practical example in a Ruby application.
In this guide, I'll focus on a simpler yet powerful example using only SQL, so if you want to follow me in this adventure, make sure you have PostgreSQL installed.
That's the only requirement. No more tools to install or setup. Postgres solely.
Seeding data
In order to explain further the fundamentals of textual search, relevance and results ranking, we have to seed our database with real data and compare different search strategies.
Let's create a table called courses containing only a title and description columns. Those columns will be our "searchable" columns in which we will perform a text search against:
CREATE TABLE courses
(id SERIAL PRIMARY KEY,
title VARCHAR(80) NOT NULL,
description VARCHAR(200) NOT NULL);
Next, we will populate the table with some dummy data:
INSERT INTO courses (title, description) VALUES
('Improve your sales skills', 'A complete course that will help you to improve your sales skills'),
('Intro to Computer Science', 'Understant how computers work'),
('Law 101', 'Have you ever wondered doing some Law?'),
('Natural Sciences the easy way', 'Your guide to understand the world'),
('Mathematics: a gentle introduction', 'Numbers are easy'),
('The crash course of Data Science', 'Be a data scientist in 5 weeks'),
('Sales crash course', 'Yet another course on Sales'),
('Java in a nutshell', 'Learn Java in 21 days'),
('Ruby programming language', 'DDH sales Ruby, but could you buy it?'),
('Sales matter', 'Really?'),
('History in 3 pages', 'Can you learn history in 3 pages?'),
('Mastering Git', 'Git history will no longer bother you'),
('Cooking like a boss', 'Be the next master chef'),
('Master Chef 3.0', 'Cooking revisited'),
('Functional Programming in a nutshell', 'Learn FP in 4 days');
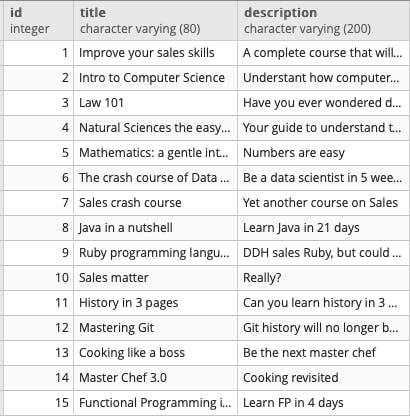
Check the data was properly created:
SELECT * FROM courses;
Cool. Now, before going to "full-text search", let's perform a simple textual search as used in many SQL systems: pattern matching
Textual search using LIKE and ILIKE
Textual search using LIKE is pretty straightforward as doing:
SELECT
courses.id,
courses.title,
courses.description
FROM
courses
WHERE
courses.title LIKE '%java%' OR courses.description LIKE '%java%'
But it returned no results, since the LIKE is case-sensitive, which means we have to specify the upcase letter as saved in the table:
...
courses.title LIKE '%Java%' OR courses.description LIKE '%Java%'
8 "Java in a nutshell" "Learn Java in 21 days"
We are lucky today, then let's use the ILIKE which is case-insensitive, so there's no need to upcase as it will perform pattern matching on either capital and non-capital letters:
...
courses.title ILIKE '%java%' OR courses.description ILIKE '%java%'
8 "Java in a nutshell" "Learn Java in 21 days"
Considerations on LIKE/ILIKE
Many systems use the pattern matching feature to implement very simple text searches. It can be enough for many scenarios but the more the platform grows in demanding users, the more search needs to return better results, with a more accurate relevance and ranking.
According to the official Postgres documentation, the pattern matching LIKE | ILIKE lacks essential properties required by modern systems:
They provide no ordering (ranking) of search results, which makes them ineffective when thousands of matching documents are found.
They tend to be slow because there is no index support, so they must process all documents for every search.
There is no linguistic support, even for English. Regular expressions are not sufficient because they cannot easily handle derived words...
For a more practical example, and being that we give more relevance for the title over description, let's see in action the ILIKE lacking such a requirement:
SELECT *
FROM courses
WHERE courses.title ILIKE '%sales%' OR courses.description ILIKE '%sales%'
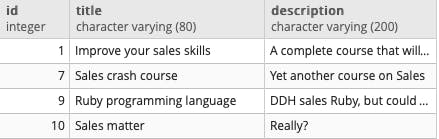 Not good.
Not good.
We want the course 10, which contains the word "Sales" in its title, to appear before the course 9, which holds the word in its description.
Furthermore, which would be our order criteria? How about ordering by a "score" so we can build a rank of our results?
Full-text search for the rescue.
Full-text search in PostgreSQL
Full-text searching (FTS) allows documents to be preprocessed and an index saved for later rapid searching and ranking. Please refer to the official documentation which is quite complete and provides all the information needed to understand and implement a FTS.
The main building blocks for FTS in PG (Postgres) are:
tsvector, which represents a searchable documenttsquery, which is the search query to perform against a document
tsvector
The to_tsvector function parses an input text and converts it to the search type that represents a searchable document. For instance:
SELECT to_tsvector('Java in a nutshell')
...will give the following:
"'java':1 'nutshel':4"
- the result is a list of lexemes ready to be searched
- stop words ("in", "a", "the", etc) were removed
- the numbers are the position of the lexemes in the document:
java:1starts at the 1st position whereasnutshell:4starts at the 4th position
tsquery
The to_tsquery function parses an input text and converts it to the search type that represents a query. For instance, the user wants to search "java in a nutshell":
SELECT to_tsquery('java & in & a & nutshell');
...will give the following:
"'java' & 'nutshel'"
- the result is a list of tokens ready to be queried
- stop words ("in", "a", "the", etc) were removed
So, how to match a query against a document?
The @@ operator
The @@ operator allows to match a query against a document and returns true or false. Simple as that.
/* true */
SELECT to_tsquery('java & in & a & nutshell') @@ to_tsvector('Java in a nutshell');
/* true */
SELECT to_tsquery('java') @@ to_tsvector('Java in a nutshell');
/* true */
SELECT to_tsquery('nutshell') @@ to_tsvector('Java in a nutshell');
/* false */
SELECT to_tsquery('batatas') @@ to_tsvector('Java in a nutshell');
Yay! As for now, we have the essential requirements to implement FTS on our courses table.
Search against courses
Let's perform the basic full-text search, looking for courses containing "java" in their titles:
SELECT *
FROM courses
WHERE to_tsquery('java') @@ to_tsvector(courses.title)
8 "Java in a nutshell" "Learn Java in 21 days"
Great. Let's perform the search "sales" against the title and description as well:
SELECT *
FROM courses
WHERE to_tsquery('sales') @@ to_tsvector(courses.title || courses.description)
or
SELECT *
FROM
courses,
to_tsvector(courses.title || courses.description) document
WHERE to_tsquery('sales') @@ document
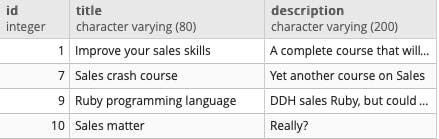
At this moment, the results are similar to our ILIKE version. Let's see where the FTS really shines.
ts_rank
The ts_rank function takes the document and query as arguments attempts to measure how relevant are documents to a particular query.
SELECT
ts_rank(
to_tsvector('Java in a nutshell'),
to_tsquery('java')
)
"0.06079271"
Checking multiple variations:
/* 0.06079271 */
SELECT ts_rank(to_tsvector('Java in a nutshell'), to_tsquery('nutshell'))
/* 0 */
SELECT ts_rank(to_tsvector('Java in a nutshell'), to_tsquery('batatas'))
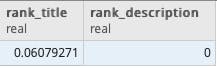
A more sophisticated simulating a rank of potential titles and descriptions:
SELECT
ts_rank(
to_tsvector('Java in a nutshell'),
to_tsquery('java')
) AS rank_title,
ts_rank(
to_tsvector('Learn in 21 days'),
to_tsquery('java')
) AS rank_description
Great! Now we have all the needed to implement a better textual search with proper ranking against our courses.
Search courses with ranking
Ranking results means that we have to split the document in different rankings so we can perform ordering accordingly.
We basically need to export the ranking fields:
SELECT
...
ts_rank(to_tsvector(courses.title), query) as rank_title,
ts_rank(to_tsvector(courses.description), query) as rank_description
...
...and perform the query against the whole document containing either title and description:
FROM
...
to_tsvector(courses.title || courses.description) document,
to_tsquery('sales') query
WHERE query @@ document
...
Then we are ready to perform the correct ordering:
...
ORDER BY rank_description, rank_title DESC
The implementation with ranking
So here we have a implementation of a full-text search with ranking in PostgreSQL in just 12 lines of SQL code:
SELECT
courses.id,
courses.title,
courses.description,
ts_rank(to_tsvector(courses.title), query) as rank_title,
ts_rank(to_tsvector(courses.description), query) as rank_description
FROM
courses,
to_tsvector(courses.title || courses.description) document,
to_tsquery('sales') query
WHERE query @@ document
ORDER BY rank_description, rank_title DESC

Is it fast?
Depending on the amount of data, such a query may face performance issues, since it needs to convert data to searchable documents on the fly.
Index for the rescue
Creating the proper index (a GIN index for text search), it can improve the performance by orders of magnitude.
In this project I made a proof of concept in which 12 millions of cities could be searched in just a few milliseconds. GIN index only. No materialized view needed.
Let's see how a GIN index could be created for our courses table:
CREATE INDEX courses_search_idx ON courses USING GIN (to_tsvector(courses.title || courses.description));
And we are good.
Just sit down, relax and enjoy a search across millions of courses with no performance issues.
How about fuzzy searching?
Fuzzy search, or "string approximation matching", is the technique used to calculate the approximation of two strings. It's commonly used to anticipate mispellings on the queries and so on.
Unfortunately, the Postgres built-in FTS doesn't support fuzzy searching, however, by using an extension, we can combine full-text search and fuzzy search in the same SQL query.
Let's create the extension:
CREATE EXTENSION pg_trgm
Now we can see the differences in action:
SELECT
to_tsquery('jova') @@ to_tsvector('Java in a nutshell') AS search,
SIMILARITY('jova', 'Java in a nutshell') as similarity

Note that searching for "jova" against a a text "Java in a nutshell", the full-text search match operator returns false whilst the SIMILARITY function, provided by the pg_trgm extension, returns a value 0.09.
In a scale from 0 to 1, similar strings tend to be close to 1.
The final implementation, using ranking and fuzzy search
So here we have a implementation of a full-text search with ranking and fuzzy search in PostgreSQL in just 16 lines of SQL code:
SELECT
courses.id,
courses.title,
courses.description,
rank_title,
rank_description,
similarity
FROM
courses,
to_tsvector(courses.title || courses.description) document,
to_tsquery('curse') query,
NULLIF(ts_rank(to_tsvector(courses.title), query), 0) rank_title,
NULLIF(ts_rank(to_tsvector(courses.description), query), 0) rank_description,
SIMILARITY('curse', courses.title || courses.description) similarity
WHERE query @@ document OR similarity > 0
ORDER BY rank_title, rank_description, similarity DESC NULLS LAST
Highlights:
- we apply the similarity function against the title and description
- when the search has no match, we filter the results which have a similarity above 0
- added the
NULLIFfunction so when therank_*is zero, we cast the value toNULLso the ordering can consider NULL values to be the last in ranking results
Conclusion
This guide was quite heavy but it covered only the very basics of full-text search in Postgres. In the official documentation you can see much more features and capabilities, such as highlight documents, weights, query tree, query rewrite, dictionaries, triggers and so on.
It's reliable and fast, which means that it can be used in a wide range of requirements, from simple search systems to complex ones. In case you already have PostgreSQL in your stack, it's worth considering to experiment on it before going to an external/expensive alternative which will demand more attention to operations complexity.
I hope you could enjoy this ride of implementing FTS in PostgreSQL. Happy searching!